Exception Handling dan Event Handling
Exception
Dalam melakukan pemrograman pasti pernah terjadi kesalahan, hal tersebut secara otomatis akan dilemparkan dalam bentuk objek yang disebut sebagai exception. Secara lebih rinci, exception merupakan suatu event yang terjadi selama eksekusi program dan mengacaukan aliran normal instruksi program. Dalam menangani sebuah exception, Java menggunakan mekanisme penanganan exception terstruktur.
Contoh kasus yang sering dialami yaitu sebuah program apabila mengalami kesalahan akan menghasilkan suatu runtime errors seperti gagal membuka file. Ketika runtime error terjadi, maka aplikasi akan membuat suatu exception.
Exception juga memiliki berbagai macam operasi yang dapat terbagi menjadi 3 bagian besar yaitu
- Claiming an exception: ketika error terjadi di suatu method, maka method akan membuat objek yang kemudian dikirim ke runtime sistem.
- Throwing an exception: proses pembuatan exception objek dan melakukan pengiriman ke runtime sistem.
- Catching an exception: penyerahan exception dari sistem ke handler
Terdapar kategori exception seperti berikut ini:
- Checked exceptions: disebabkan oleh kesalahan pemakai program atau hal yang dapat diprediksi oleh pemrograman.
- Runtime exception: disebabkan oleh kesalahan program atau pada desain program.
- Errors: walaupun error bukan merupakan exception, namun hal ini merupakan masalah yang muncul diluar kendali pemakai. Terdapat bebagai jenis error yaitu:
- Syntax error: kesalahan dari penulisan syntax sehingga tidak dapat dieksekusi.
- Logical error: kesalahan yang disebabkan kesalahan penulisan atau rumus yang diterapkan oleh programmer.
- Runtime error: kesalahan akibat kecerobohan dari programmer yang biasanya terjadi miskomunikasi antara program dan file yang dipanggil di dalam program.
- Menangani Exception ( Exception Handling )
Untuk mengatasi kesalahan sewaktu program dieksekusi, Java menyediakan exception handling yang dapat digunakan untuk hal-hal berikut:
- Menangani kesalahan dengan penulisan kode penangan kesalahan yang terpisah dari kode awal.
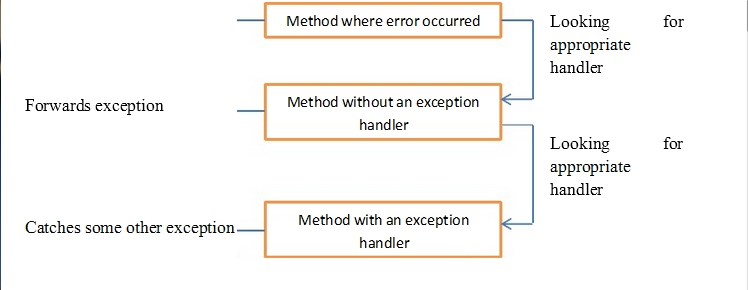
- Menyediakan mekanisme yang memungkinkan untuk menjalankan kesalahan yang terjadi dalam sebuah metode ke metode yang melakukan pemanggilan metode itu.
- Menangani berbagai jenis kondisi yang abnormal.
Keyword Exception Handling
1. Throw
Saat terjadi exception, maka akan terbentuk exception objek dan runtime pada Java akan berjalan untuk melakukan penanganan. Kita dapat melemparkan exception tersebut secara eksplisit dengan keyword throw.
Syntax : throw variableObject;
Aliran eksekusi akan segera terhenti setelah pernyataan throw dan pernyataan selanjutnya tidak akan dicapai. Block try terdekat akan diperiksa untuk melihat catch yang cocok dengan tipe instace throwable. Bila benar, blok try akan diperiksa. Bila tidak, blok try selanjutkan akan diperiksa sampai menemukan blok try yang bermasalah.
2.Throws
Digunakan untuk mengenali daftar exception yang mungkin di throw oleh suatu method. Jika tipe exception adalah error atau runtime exception maka aturan ini tidak berlaku karena tidak diharapkan sebagai bagian normal dari kerja program.
Syntax: Type method-name(arg-list) throws exception-listy{}
3.Try Catch
Digunakan untuk mengesekusi suatu bagian program, bila muncul kesalahan maka sistem akan melakukan throw suatu exception yang dapat menangkap berdasarkan tipe exception atau yang diberikan finally dengan penagann default.
Syntax: try { //Code// } catch ( ExceptionName ) { //Code// }
4, Finally
Digunakan untuk membuat blok yang mengikuti blok try. Blok finally akan selalu dieksekusi, tidak peduli exception terjadi atau tidak. Sehingga, menggunakan keyword finally memungkinkan untuk menjalankan langkah akhir yang harus dijalankan tidak peduli apa yang terjadi di bagian protected code.
- Checked dan Unchecked Exceptions
Checked exception merupakan exception yang diperiksa oleh Java compiler yang memeriksa keseluruhan program apakah menangkap exception yang terjadi dalam syntax throws. Apabila checked exception tidak ditangkap, maka compiler akan error. Tidak seperti checked exception, unchecked exception tidak berupa compile time checking dalam exception handling dikarenakan pondasi dasar unchecked exception adalah error dan runtime exception.

- Metode Throwable Class
Terbagi menjadi 5 macam metode:
- Public String getMessage(): megembalikan pesan pada saat exception memasuki constructor.
- Public String getLocalizedMessage(): subclass dapat overide untuk mendukung pesan spesifik lokal yang disebut sebagai pemanggilan program.
- Public synchronized Throwable getCause(): untuk exception yang null
- Public String toString(): mengembalikan informasi dan pesan lokal.
- Public void printStackTrace: mencetak stack trace.
- Event Handling
Event handling merupakan suatu konsep penanganan terhadap aksi yang terjadi. Sebagai contoh, jika kita klik buttonklik maka akan ditampilkan sebuah pop up. Hal sederhana ini merupakan contoh dari event handling. Masih banyak berbagai contoh mengenai event handling yang tidak hanya buttonklik saja.
Dalam event handling, terdapat empat bagian penting yang harus diketahui:
- Event object merupakan objek yang mendeskripsikan sebuah event yang di trigger oleh event source.
- Event handler merupakan method yang menerima event object dan melakukan respon yang sesuai dengan event object.
- Event listener merupakan interface yang akan melakukan handle terhadap event yang terjadi. Listener harus diimplementasikan oleh class yang akan melakukan handle terhadap event.
- Event source merupakan pembangkit sebuah event object.
Untuk dapat melakukan listener, diperlukan sebuah class yang terdapat pada java.awt.event.*;.
Dengan demikian, event terbagi menjadi beberapa kategori seperti:
- Action merupakan interface dari ActionListener dengan method actionPerformed.
- Item merupakan interface dari ItemListener dengan method itemStateChange.
- Mouse merupakan interface dari MouseListener dengan lima method yaitu:
- mouseClicked
- mousePressed
- mouseReleased
- mouseEntered
- mouseExited
- Mouse motion merupakan interface dari MouseMotionListener dengan method mouseDragged.
- Focus merupakan interface dari FocusListener dengan dua method yaitu:
- focusGained
- focusLast
- Window merupakan interface WindowsListener dengan empat method yaitu:
- windowClosing
- windowOpened
- windowActivated
- windowDeactived
Setiap event object memiliki tipe event yang berbeda sehingga kita harus menentukan tipe event sebelum menentukan jenis interface listener karena tipe event memiliki jenis interface yang bersesuaian.
Berikut merupakan tipe event yang ada di bahasa Java:
- ActionEvent
- ItemEvent
- WindowEvent
- ContainerEvent
- ComponenEvent
- FocusEvent
- TextEvent
- KeyEvent
- MouseEvent
- AdjustmentEvent
Berikut juga merupakan interface listener yang terdapat pada bahasa Java:
- ActionListener: menerima event action pada suatu komponen.
- ItemListener: menerima item event.
- WindowListener: menerima aksi atas perubahan windows.
- ContainerListener
- ComponenListener
- FocusListener: menerima keyboard focus events pada sebuah komponen.
- TextListener
- KeyListener: keyboard event dihasilkan ketika sebuah key ditekan, dilepas, atau diketik.
- MouseListener: menerima mouse event pada suatu komponen.
- MouseMotionListener: menerima mouse motion event.
- AdjustmentListener: bereaksi terhadap perubahan yang terjadi.
Berikut merupakan tahapan mengenai cara melakukan event handling dalam Java:
- Deklarasikan class yang akan melakukan event handle yang terjadi dan tuliskan kode yang menyatakan class tersebut mengimplementasikan interface listener.
- Event source mendaftarkan sebuah listener melalui method add<type>Listener
- Kode yang mengimplementasikan method pada interface listener pada class akan melakukan event handle.